


When you add up all the typographical characters belonging to all the world’s writing systems—not just the Latin alphabet used in the familiar European languages, mind you, but Russian Cyrillic, Japanese katakana, the Khmer script of Cambodia, Arabic, Greek, Hindi Devanagari, Hebrew, and all the rest—they number in the hundreds of thousands. The Unicode Consortium, the nonprofit organization that standardizes and administers the presentation of writing systems in computer applications and on the World Wide Web, has thus far assigned a reference point in the information architecture underpinning modern text processing to every mark used in 159 unique scripts. These include living tongues like those listed above, alternative writing systems such as Braille, and even a number of historical curiosities, from Babylonian cuneiform to Viking runes to Egyptian hieroglyphics.
Unicode remains a work in progress. Compiling every mark ever used for communication at any time in history may not even be an achievable goal. But even in its current state, the standard defines 144,532 distinct glyphs. If each were assigned to a single unique key, you’d need a computer keyboard the size of a ping-pong table to fit even a fraction of them.
Get a free sample proofread and edit for your English document.
Two professional proofreaders will proofread and edit your English document.
But there are only ninety-four choices readily apparent on your standard QWERTY keyboard. You’ve got forty-seven keys: the twenty-six letters of the standard Latin alphabet, plus ten numbers and eleven miscellaneous punctuation keys, each with two variations accessible via the Shift key.
Stolen Goods
Given the mongrel nature of the English language, its glorious mishmash of Germanic and Latin structures with a French vocabulary, and its tendency to pilfer any useful word that’s not nailed down regardless of source, it’s actually pretty amazing that those ninety-four glyphs will get you as far as they do. I’m more than 300 words into writing the blog you’re reading right now, for instance, and except for a couple of em dashes, I haven’t had to venture beyond the typographical symbols at my fingertips.
We’ve spent the recent months looking at different ways to render these nonstandard characters in Microsoft Word, the characters not available among the ninety-four choices on a standard keyboard, which include not only letters with diacritical marks, but also phonetic pronunciation symbols, among other things. Most of those methods have relied in one way or another on the principle of copy-and-paste, which is OK if you use such characters only once in a great while. But for someone who needs diacritics on a regular basis, they’re a little clumsy. If you are, say, a film scholar, it can interrupt your white-hot creative flow to have to search, copy, and paste multiple times whenever you need to type the phrase “cinéma vérité,” which may be multiple times while writing a single piece.
Enter Unicode
The curators of the standard have assigned keystroke shortcuts the diacritics, punctuation marks, and symbols most commonly used in English, allowing users to render them onscreen and in print while typing and without opening a separate application or subroutine. And because Unicode is a cross-platform standard, these keystroke shortcuts work not only in Word, but also in any application that lets you enter text: word processing and desktop publishing programs, presentation software like PowerPoint, image editing programs, email clients, social media platforms, and content management systems such as WordPress.
Two-Hand Touch
As noted last month, the Alt key (located to the left and right of your space bar) unlocks these keystroke shortcuts, as long as you have a separate keypad for numbers on your keyboard. (Be sure NumLk is on!) Holding down Alt while entering a sequence of digits lets you render hundreds of characters and symbols. Holding down Alt with your left hand while using the dedicated numeric keypad with your right, as shown below, is the quickest and most efficient technique, I’ve found.

If you don’t have a separate keypad or if the code has letters in it, and if you’re working with Microsoft Word, WordPad, Outlook, or another Microsoft app, type in the four-character code and press AltX. So, for example, the Unicode I want is U+A19C, so I type in “a19c” and hit AltX, and I get ꆜ.
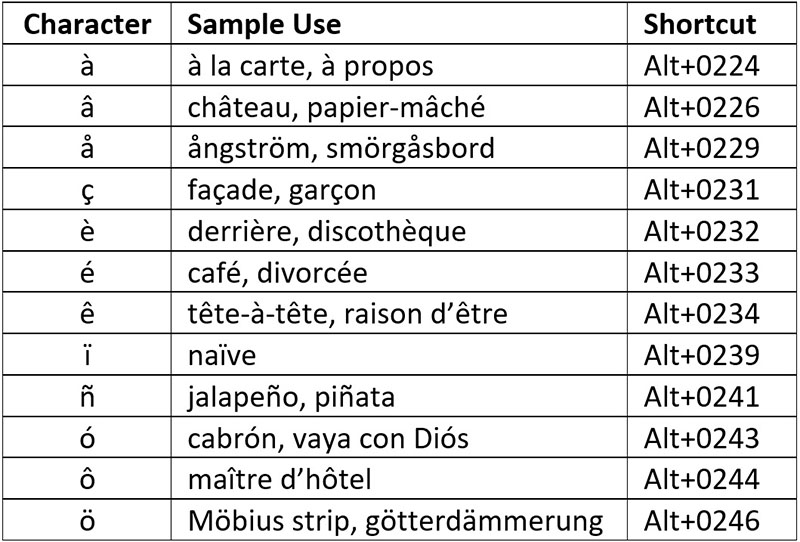
Memorizing just a few keystroke combinations will give you quick access to your most commonly used diacritic characters. You’ll want to think about your own writing, and take a look at the Character Map utility, which we discussed last month, to determine which combos you’ll want to commit to memory. Below is a cheat sheet of the diacritic combinations I use most frequently, some more frequently than others.
That wraps up our (long!) look at the uses and methods for diacritical marks. I hope you’ve found it useful. As always, if there’s a topic related to editing, proofreading, or word processing that you’d like me to explore in a future blog, let me know in the comments.
Jack F.
Get a free sample proofread and edit for your English document.
Two professional proofreaders will proofread and edit your English document.
Get a free sample proofread and edit for your document.
Two professional proofreaders will proofread and edit your document.
We will get your free sample back in three to six hours!


© 2010 - 2020 ProofreadingPal LLC - All Rights Reserved.

